This book contains both practical guides on exploring missing data, as well as some of the deeper details of how naniar works to help you better explore your missing data. A large component of this book are the exercises that accompany each section in each chapter.
The following object is masked from 'package:naniar':
impute_median
In this chapter we discuss methods for assessing model inference across differently imputed datasets. Let’s step back, and think about why we are imputing data in the first place. Our goal in performing imputations is to perform an analysis in a way that the missing values do not unfairly bias subsequent inference, or predictions that we make.
15.1 Exploring parameters of one model
[TODO: update from airquality dataset, it is getting a bit tired]
Let’s fit a model to the airquality dataset using a linear model, predicting temperature, using ozone, solar radiation, wind, month and day.
Complete case analysis, where we remove all rows that contain a missing value
Imputing data using the linear model imputation from the last lesson.
Using the complete cases provides a nice baseline for comparison, as this removes all missing values, so it is sort of like comparing your model to “doing nothing”. Except that it is worse than doing nothing - since you are removing data! You might be able to imagine a few different outcomes of this process:
The outputs are basically the same, in which case, using the data with imputed values is better from a statistics standpoint, so you may as well use them.
The imputed data does much better than complete cases, in which case, use the imputed data.
The imputed data does worse than complete cases - which which case, you might want to check your imputed model for errors, or perhaps there are some bias in your data.
15.2 Combining the datasets together
There are three steps to comparing our data.
First, we perform the complete case analysis, using na.omit(), and converting the data into nabular form.
Second, we impute the data according to a linear model
#2. Imputation using the imputed data from the last lessonaq_imp_lm <- airquality %>%nabular() %>%add_label_shadow() %>%as.data.frame() %>%impute_lm(Ozone ~ Temp + Wind + Month + Day) %>%impute_lm(Solar.R ~ Temp + Wind + Month + Day) %>%as_tibble()
Finally, we combine the different datasets together with bind_rows(). Note the extra column, imp_model, which helps us identify data from the model used.
This involves some functions that we haven’t seen before. Let’s unpack what’s happening below. First we group by the imputation model, then nest the data. This collapses, or nests, the data down into a neat format where each row is one of our datasets.
bound_models %>%group_by(imp_model) %>%nest()
# A tibble: 2 × 2
# Groups: imp_model [2]
imp_model data
<chr> <list>
1 cc <tibble [111 × 13]>
2 imp_lm <tibble [153 × 13]>
This allows us to create linear models on each row of the data, using mutate, and a special function, map. This tells the function we are applying to look at the data and then fit the linear model to each of the datasets in the data column.
bound_models %>%group_by(imp_model) %>%nest() %>%mutate(mod =map(data, ~lm(Temp ~ Ozone + Solar.R + Wind + Day + Month, data = .)))
# A tibble: 2 × 3
# Groups: imp_model [2]
imp_model data mod
<chr> <list> <list>
1 cc <tibble [111 × 13]> <lm>
2 imp_lm <tibble [153 × 13]> <lm>
Then we then fit the model and create separate columns for residuals, predictions, and coefficients, using the tidy function from broom, to provide nicely formatted coefficients from our linear model.
# A tibble: 2 × 6
# Groups: imp_model [2]
imp_model data mod res pred tidy
<chr> <list> <list> <list> <list> <list>
1 cc <tibble [111 × 13]> <lm> <dbl [111]> <dbl [111]> <tibble [6 × 5]>
2 imp_lm <tibble [153 × 13]> <lm> <dbl [153]> <dbl [153]> <tibble [6 × 5]>
Our data, model_summary, has the columns imp_model, and data, and columns with our fitted linear model (mod), residuals (res), predictions (pred), and tidy coefficients (tidy).
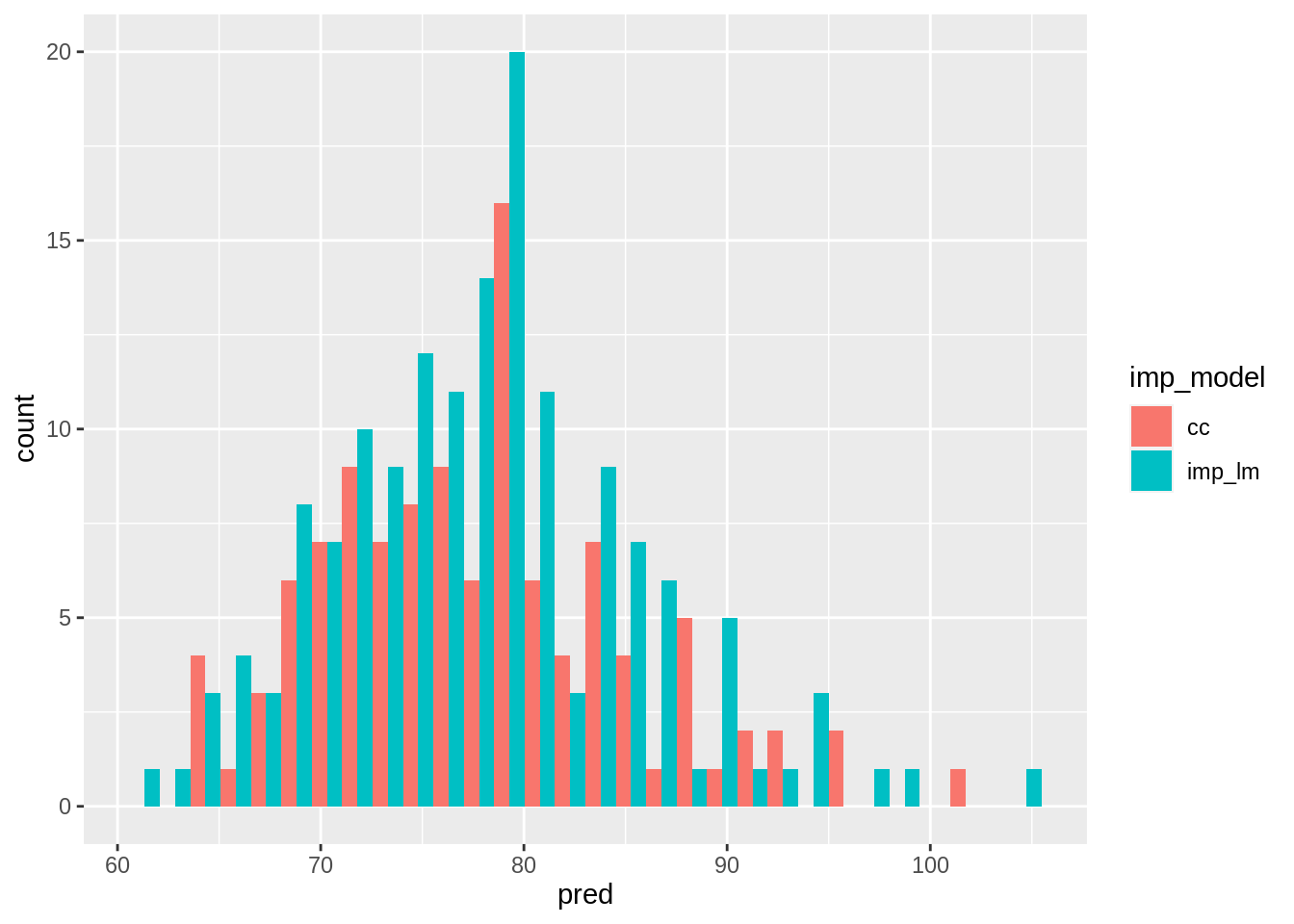
model_summary forms the building block for the next steps in our analysis, where we are going to look at the coefficients, the residuals, and the predictions.
This is just one way to fit these kinds of models - there are many other ways, and it might not work for all types of models, but this many models approach can be convenient!
15.4 Exploring coefficients of multiple models
We explore coefficients by selecting the imputation model and the tidy column and unnesting:
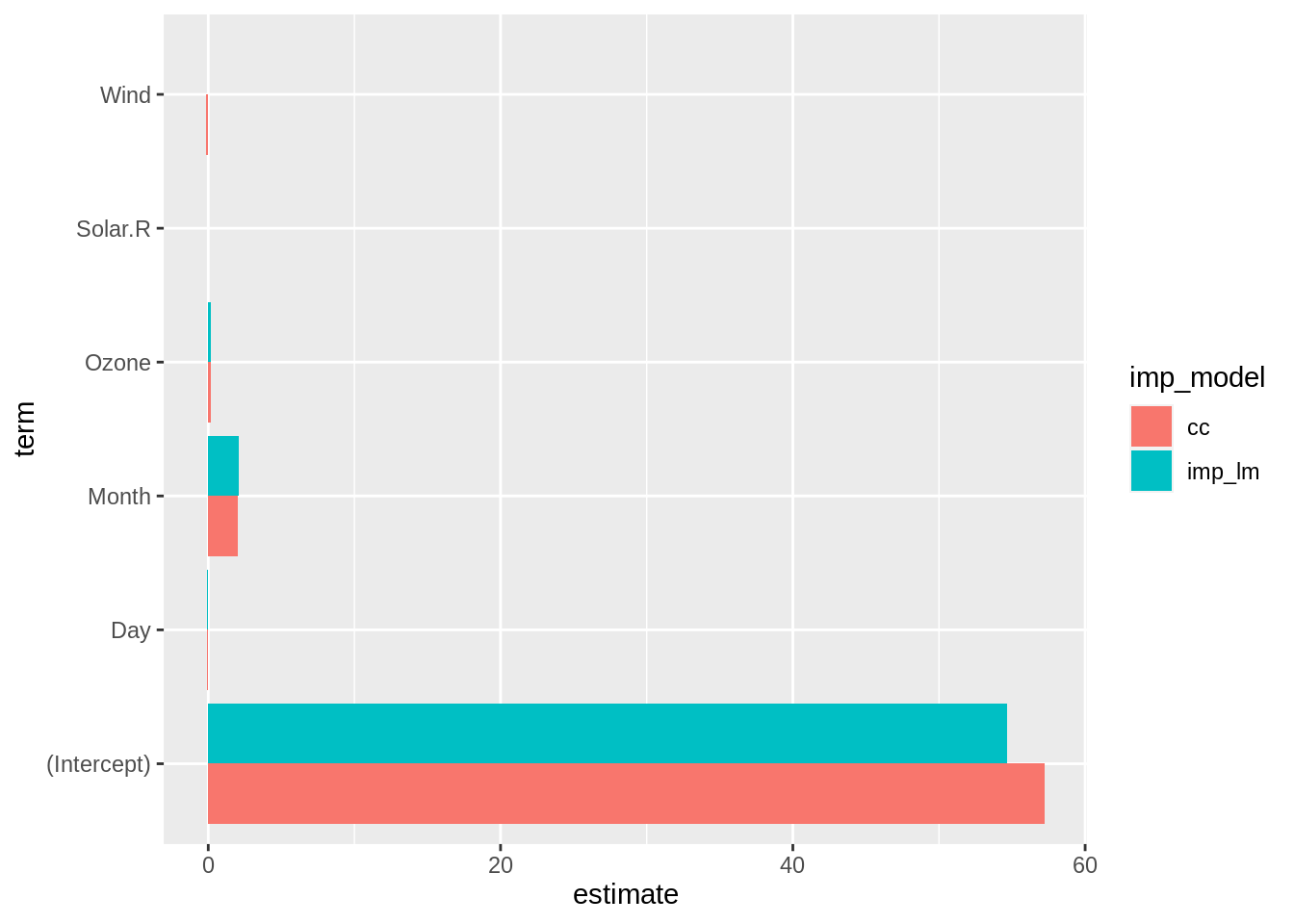
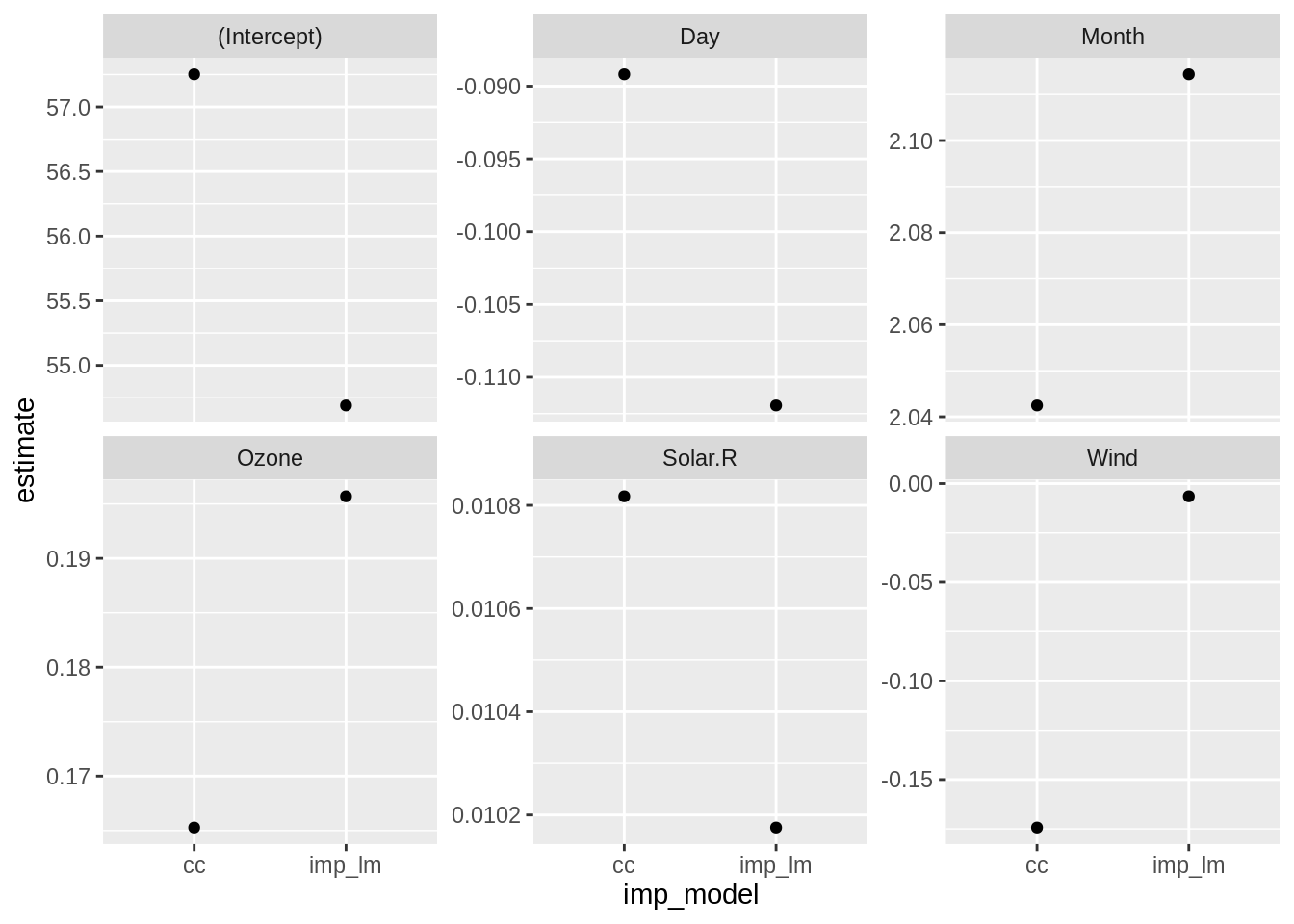
Plotting these, we see that the estimates are pretty much the same for both, with the intercept being slightly lower for the imputed model, and higher for the complete cases. However, we can probably get a slightly more nuanced view of this by looking at these variables on their own scale:
These look like big differences for all of these - but this is intentional, as we have let the y axis be freely varying. These values in this case look to be not very different in a meaningful way for this data, but it is an important step to take for any dataset.
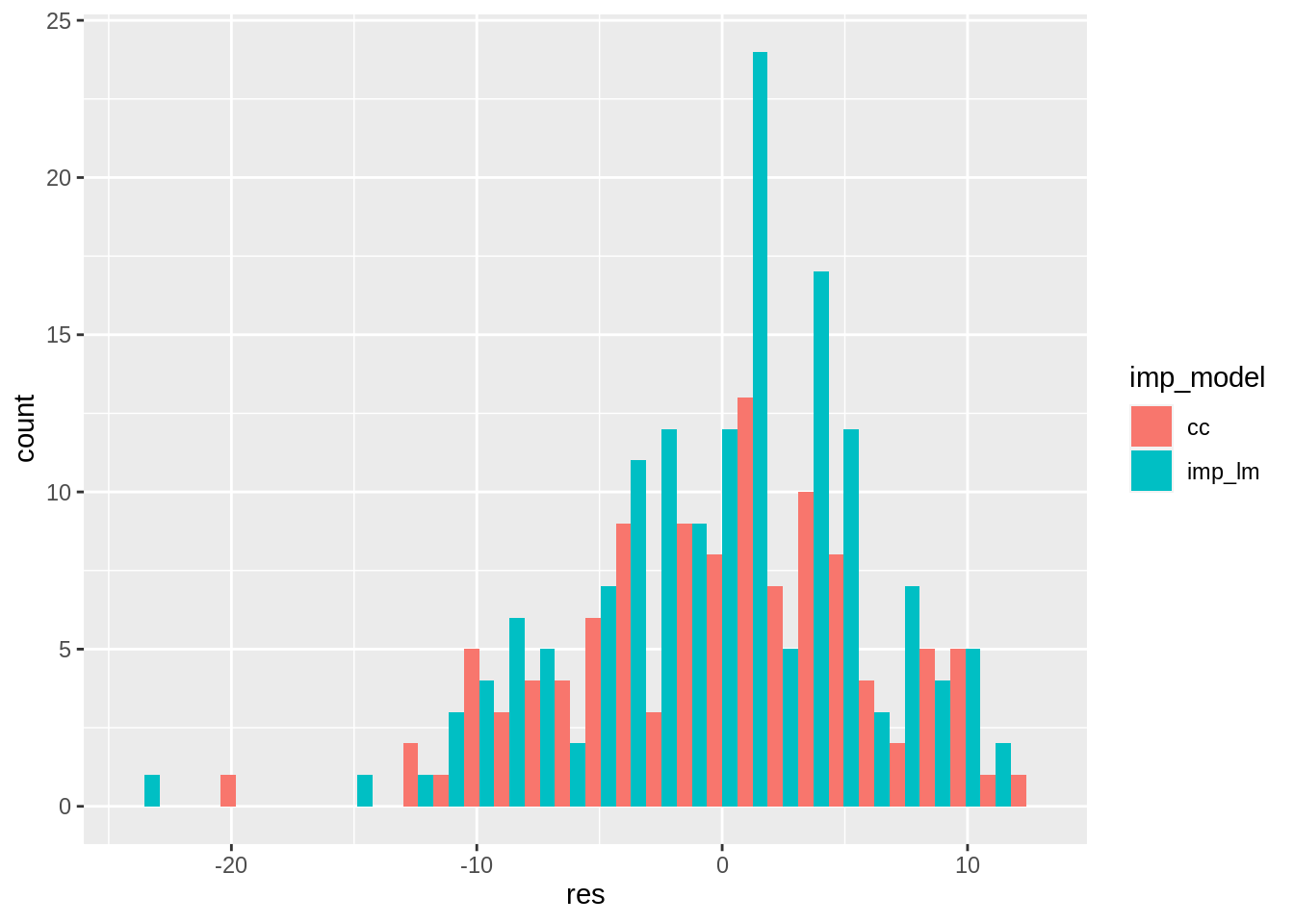
15.5 Exploring residuals of multiple models
Let’s explore the residuals by selecting the imp model and residuals, and then unnesting the data. We can then create a histogram, using position = "dodge" to put residuals for each model next to each other.